Hello All,
In this blog we will try to understanding what microservices are and what are the different integration patterns in which microservices are implemented.
Lets first understand what are microservices
Micro Service is independently deployable service modeled around a
business domain. It is a method of breaking large software applications into
loosely coupled modules, in which each service runs a unique process and
communicates through APIs. It can be developed using messaging or event-driven
APIs, or using non-HTTP backed RPC mechanisms.
Micro Services are designed to cope with failure and breakdowns of large
applications. Since multiple unique services are communicating together, it may
happen that a particular service fails, but the overall larger applications
remain unaffected by the failure of a single module.
Now the question arises what is the need to implement microservices when we have integrated different systems for atleast a decade now.
The answer is in the below table

{kind=link}
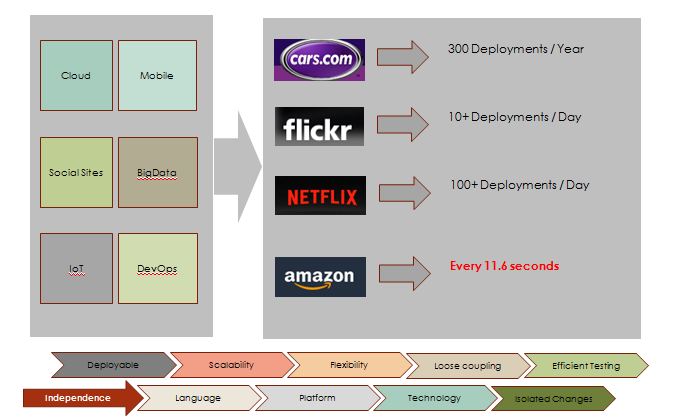
Gone are the days when we used to have 3-4 releases in a year. The current business demands us to roll out new features and application more frequently and with very minimal or no downtime.
In the example above, we can see how the releases have changes and now code can be deployed more frequently like the case of amazon where they deploy the code into production every 11.6 seconds
There are different integration patterns using which one can implement microservice and cater to the continuous changing business needs.
We will try to understand it with an banking example.
Let’s assume that we are responsible for building an
application for managing a Banks day-to-day operations. Among the many things that our application
will have to do, we’ll focus on:
- Managing Debate and Credit cards transaction
- Managing the net banking transaction
- Managing lending transaction
Now, let’s say a customer swipes his debate card. What should our
application do? It should certainly update the customers record. It should also initiate the transaction in net banking module. It also makes debate of the debate
card transaction and update the available balance in the net banking module
In a monolithic architecture, using a single
relational database for
the whole application, would be straightforward. In the same process and
transaction, we can update the customer record, mark any available balance changes, and insert the customers record into the
corresponding table. In case of errors,
we can rollback the transaction.

On the other hand, in a distributed microservices architecture, it can
start to get complicated. Let’s assume that we have the following services:
- A transaction service from cards, which manages customers transactions records
- A creditCheck service, which manages the customers bankings operations
- An lending service, which manages customers mortgage and lending's
Remember that each service manages its own data, so that
when the transaction Service is triggered with a transaction when the customer swipes
his card, it not only has to update its own database, but it also has to make
sure that the other relevant services are also notified. This is critical for
maintaining consistency in the application. But which is the best way for a service to notify
other interested services of events or changes?
To understand it more, refer below example with pointers for the different transaction involved and different systems / applications which help implement it.

mS-
> JDBC -> MQ -> 3rd
Party
- User initiates Transaction by swiping Card
- Card systems confirms the availability of fund with net banking
- Net banking send the confirmation to process transaction
- Net banking send request to process notification based on the preference given by user [SMS, eMail] to Notification system
- Notification system creates entry in audit tables and send notification message to outbound queue
- 3rd Party system consumes the message, process the message and returns acknowledge message to banking notification system by adding the acknowledge to its outbound queue
- Notification system updates the confirmation to Cards and Net banking system
- 3rd party delivers the message to end users with confirmation of transaction

Database sharing is one the
easiest and fastest way of sharing data across multiple services. In our case,
we could create a new service, whose sole responsibility will be to keep the
three databases in sync. The service could run a batch job every so often, in which
it fetches from the Cards
database the latest
unprocessed transactions.
Then, for each
relevant record, it could update the other two services’ databases.
You’ll notice that the new
sync service has direct access to the three databases. This means that changes to any of the three services’ database
schemas will also affect the
new sync service. One of
the fundamentals of microservices architectures is
that each service/team owns its own data.
This allows for development teams to make internal changes to their services without affecting any other services
as well as enabling every
team to deploy their
services independently, with minimum coordination from other teams. By allowing other
services to access their database, we’re increasing the coupling between services and
teams and introducing friction into the release process. But what would happen to
the other services if the shared tables’ schemas changes? And in any case who is responsible for those tables now
anyway?
These two factors alone are
enough for rejecting this solution because as a general rule we want to avoid
solutions in which multiple services access the same database. Especially when those services
are owned by different teams. For example, you might consider having the transaction service update the other services’ databases directly.

Probably the most
intuitive way of integrating our services would be using REST. Both the Cards, Net Banking
and Lending Services
can define a dedicated REST endpoint that other services can use to notify them
of the transactions. In this case the Cards transaction
Service will call these two
endpoints when it processes a new transaction.
The advantage of this approach is clear: the
implementation details of each service remain private. As long as the REST
interface is not changed, each team can make any internal change it needs to
its service with minimum coordination with other teams. However, this approach
doesn’t come without its own set of problems.
As you probably know, REST works synchronously. There
two major downsides to using synchronous communication
Temporal
Coupling
We’ll have a problem if either the Cards or Net banking
Service happens to be
unavailable when the transaction
Service sends them a request.
What should the Transaction
Service do? Rollback? Try again? If that
doesn’t work, then what?
The more external synchronous calls our service makes, the more dependencies it
has and the less resilient it becomes.
Every time a service calls another service
synchronously, it will block it until it receives a response. In our case, our transaction Service will have to wait for
both the creditCheck and Credit history
Services to complete their
requests before it can return its own response to the calling service or
client. This might not seem like much, but this extra latency can add up if
you’re not careful.
Also beware of cascading effects: when there is long chain of services
communicating with each other via REST, one slow-responding service can slow
down all the other services up the chain.
Another issue with this approach is that the calling
service has to be aware of any external service that might need to get notified
when an interesting event happens. We’ll need to modify our credit service every time that a new
service will want to get notified of a new transaction.

We can easily decouple the caller and callee services by putting
a message
broker in the middle.
Every time it processes a new transaction, the transaction Service will publish an event to the message broker. On the
other side, the Net
banking and Lending Service will have subscribed to the message broker to receive
events about transaction
updates. Each service will
receive and process those events independently and at its own pace
The key concepts here are:
The message broker will store the messages safely until
they are processed. This means that the transaction Service will be able to process new transaction, even if the net banking or lending Services are unavailable. If
they happen to be unavailable, messages will accumulate in the message broker
and will be processed once the services are back up
The transaction Service doesn’t need to know about the net banking and
lending Services,
as it only communicates with the message broker. What’s more, we can add and
remove subscribed services just by reconfiguring the message broker, without
affecting the transaction
Service. The message broker
will receive the corresponding message and send it to all subscribed services.
This pattern is called fan-out
Events are being processed asynchronously now, which
means that the transaction
Service can return a response
as soon as it has published the event to the message broker. Other slow-working
services won’t affect our service’s response time
Subscribed Services can process events at its own pace.
If the Publisher Services sends more events than the subscribed service can
process, the message broker will act as buffer, isolating both services.
Note that we can have asynchronous communication only when
our Cards Service doesn’t need a response from the other two services.
This is not the case in cards swipe and all the transaction happens at run
time. This is possible in scenarios of Notification only as notification are of
low priority compared to transaction of the customer.
As part of the decoupling that we get by using a message
broker, the Publisher Service won’t know about the Subscribed Services (and
vice-versa). While this brings about several advantages, like we just saw, it
also means that the Subscribed Services cannot send a response back to the
Publisher Service. It would also be remiss not to mention here that using
asynchronous communication makes testing and troubleshooting more difficult
.
Another possible pattern that we haven’t considered here is
using files for sharing data between services. If you have experience with ETL
processes, you’ll probably find this approach familiar. Every X amount of time,
the transaction service could write files
containing the relevant events to a common directory (FTP, S3, HDFS, etc…). On
the other side, the Net
banking and Lending services can poll the directory for new files to process.
Since data is processed in batches, it has a
considerably large delay compared to other approaches. In addition the testing of this pattern can be
quite tricky
.
its a great article on your blog.
ReplyDeleteMicroservices Training in Hyderabad
Nice blog. You have provided such a useful informartion in this blog. Thanks for sharing.
ReplyDeleteMicroservices Training in Hyderabad
Good post and informative. Thank you very much for sharing this good article, it was so good to read and useful to improve my knowledge as updated, keep blogging. Thank you for sharing wonderful information with us to get some idea about that content.
ReplyDeleteoracle training in chennai
oracle training institute in chennai
oracle training in bangalore
oracle training in hyderabad
oracle training
oracle online training
hadoop training in chennai
hadoop training in bangalore